מהו קובץ robots.txt ואיך הוא מנחה את רובוטי הסריקה
מה הקובץ הזה באמת שולט בו - ומה שהוא לא מסוגל לעשות
קובץ robots.txt הוא מסמך טקסט פשוט שיושב בכתובת הראשית של האתר, למשל domain.co.il/robots.txt, ותפקידו להנחות את רובוטי הסריקה של מנועי החיפוש אילו דפים מותר לסרוק ואילו עדיף לדלג עליהם. שווה להבין מההתחלה שמדובר בהסכם בלתי מחייב בין האתר לבין הסורקים ולא בחוק מחייב: מנועי חיפוש גדולים כמו גוגל מכבדים את ההנחיות, אבל בוטים אחרים יכולים להתעלם לחלוטין. בגלל זה המסמך הזה משמש ככלי לניהול סריקה, לא ככלי אבטחה ולא ככלי להסתרת מידע רגיש. אם תיקייה מכילה חשבוניות או גיבויים, הגנה באמצעות סיסמה היא הפתרון הנכון ולא חסימה בקובץ רובוטס.
מניסיון מצטבר של עשרות שנים בפיתוח מערכות וקידום אתרים, ראינו את הקובץ הקטן הזה מונע שורה ארוכה של תקלות טכניות. אבל הנקודה הקריטית שרבים מפספסים היא ההבדל בין סריקה לאינדוקס: הקובץ שולט בסריקה (crawling), לא באינדוקס (indexing). גם אם חסמתם נתיב מסוים באמצעות Disallow, גוגל עדיין עלול להציג את הכתובת בתוצאות אם אתרים אחרים מקשרים אליה. מה שזה אומר בפועל? כשהמטרה היא באמת להעלים דף מתוצאות החיפוש, עדיף דווקא לא לחסום סריקה כדי שגוגל יוכל להיכנס ולראות תגית noindex או כותרת X-Robots-Tag, ואז להסיר את הדף מהתוצאות תוך שמירה על נגישות למשתמשים.
איך תקציב הסריקה משפיע על תנועה ומכירות
תקציב הסריקה (crawl budget) הוא כמות הדפים שגוגל מוכן לסרוק באתר שלכם בפרק זמן נתון. תחשבו על זה כמו מספר הביקורים שגוגל מקדיש לאתר בכל שבוע: אם הוא מרכז את הביקורים על עמודי חיפוש פנימי, פילטרים אינסופיים או שלבי checkout, הוא מגיע פחות לעמודים שמביאים כסף כמו קטגוריות ודפי מוצר. באתרים קטנים עם 50 עד 200 דפים, קובץ רובוטס לבדו כמעט לא משנה דירוגים. אבל באתרים גדולים עם 5,000 כתובות ומעלה, ההגדרות בקובץ קובעות אם גוגל יגלה תוכן חדש השבוע או ידחה את הגילוי בחודש.
נניח שיש לכם חנות אונליין שמוכרת נעלי ריצה, עם אלפי כתובות פילטר כמו ?color= או ?size= שנוצרות אוטומטית. חסימה חכמה של הפרמטרים האלו בקובץ רובוטס מפנה את תקציב הסריקה לדפי המוצר שבאמת מניעים מכירות, במקום להפנות אותו לוריאציות חסרות ערך. הקצב הזה קריטי במיוחד כשמפרסמים תוכן בתדירות גבוהה, למשל כשמייצרים מאמרים מקיפים של 1,500 מילים ומעלה באופן שוטף. ככל שגוגל מגלה את הדפים החדשים מהר יותר, ההחזר על ההשקעה בתוכן מגיע מוקדם יותר.
הפקודות הבסיסיות שכל בעל אתר צריך להכיר
הקובץ בנוי מקבוצות כללים שמתחילות ב-User-agent ואחריהן הנחיות כמו Disallow ו-Allow. גוגל מגביל את גודל הקובץ ל-500 קילובייט (KiB), שזה בערך חצי מגה, ולרוב העסקים זה שטח עצום. לכן ההמלצה המעשית היא לעבוד עם דפוסים כלליים במקום לרשום אלפי כתובות בודדות. שימו לב שנתיבים רגישים לאותיות גדולות וקטנות, כך ש-/Admin/ ו-/admin/ יכולות להוביל למיקומים שונים לגמרי.
- המונח User-agent: * מחיל כללים על כל רובוטי הסריקה של מנועי החיפוש המרכזיים.
- ההנחיה Disallow: /wp-admin/ חוסמת את לוח הניהול של וורדפרס בלי לפגוע בתוכן הציבורי.
- ההנחיה Allow: /wp-admin/admin-ajax.php שומרת על פונקציונליות חזיתית חיונית לרינדור תקין של הדף.
- הוספת Sitemap: https://www.domain.co.il/sitemap.xml מאפשרת הכנסת מפת אתר ישירות בקובץ כדי לזרז גילוי דפים.
כשיש התנגשות בין Allow ל-Disallow, גוגל בדרך כלל הולך לפי הכלל הארוך והמדויק יותר לכתובת הספציפית. הקובץ חייב לשבת בתיקיית השורש בלבד, כלומר בכתובת הראשית כמו domain.co.il/robots.txt, ומסמך שיושב בתיקייה פנימית פשוט לא נקרא על ידי אף סורק. כל תת-דומיין צריך קובץ נפרד משלו: אם יש לכם store.domain.co.il לחנות ו-blog.domain.co.il לתוכן, תצטרכו שני קבצים נפרדים. גם https מול http נחשבות גרסאות שונות, אז ודאו שהכל מפנה לגרסה אחת עקבית כדי לא להגיע למצב שבו חסמתם רק חצי מהאתר.
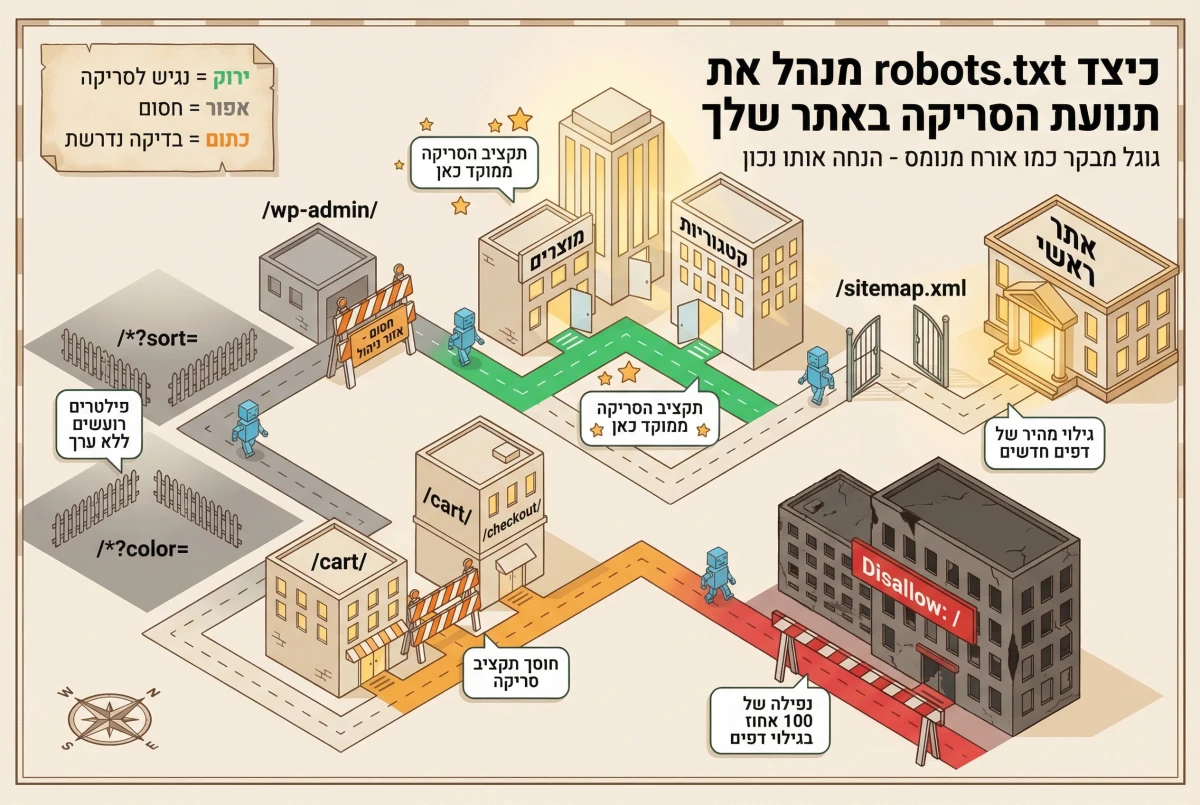
אילו טעויות נפוצות בקובץ robots.txt עלולות לחסום את האתר מגוגל
חסימה גורפת - כמו להוריד שלט "סגור" על כל החנות בגוגל
הטעות ההרסנית ביותר היא שורה אחת בודדת: Disallow: / תחת User-agent: *. הלוכסן הבודד הזה עוצר סריקה לכל האתר ומוביל לנפילה של כמעט 100% בגילוי דפים חדשים. נתקלנו בתרחיש כזה לא פעם אצל בעלי אתרים ישראליים, כשמפתח העתיק כלל מסביבת staging לפרודקשן ביום שישי לפני סוף השבוע. התיקון אמנם לקח שתי דקות, אבל חזרת החשיפות בגוגל נמשכה בין 7 ל-21 ימים.
בעיה נפוצה נוספת שמופיעה באופן מפתיע היא קובץ שנשמר בשם Robots.txt עם אות גדולה, או שנמצא בנתיב לא נכון בתוך תיקיית משנה. הסורקים מחפשים את הקובץ באותיות קטנות בלבד בתיקיית השורש, וכל סטייה מהמבנה הזה גורמת לגוגל להתנהג כאילו אין קובץ כזה בכלל. בדיקה של 3 כתובות קריטיות לפני ואחרי כל עדכון יכולה למנוע שבועות של כאב ראש.
טעויות עדינות שפוגעות ברינדור, בפרמטרים ובחשיפה
חסימה של תיקיות CSS או JavaScript כמו /assets/ או /wp-includes/ בלי חריגים היא טעות שמופיעה הרבה ב"ניקיונות ביצועים" שמתקיימים לכיוון הלא נכון. גוגל טוען את הדף כמו דפדפן כדי להבין איך הוא נראה, ואם חסמתם קבצי עיצוב או קוד, הסורק עלול לחשוב שהדף ריק או שבור. זה פוגע בהבנת התוכן ועלול לעכב שיפורי דירוג למשך 2 עד 4 שבועות. מי שמפעיל אפליקציית SPA על React, למשל, חייב לוודא שחבילות ה-JavaScript הראשיות נגישות לחלוטין, אחרת גוגל עלול לאנדקס מעטפת ריקה.
דפוסי Wildcard גם עלולים לגרום נזק. לדוגמה, Disallow: /*? אולי חוסם פרמטרי מעקב מיותרים, אבל בפלטפורמות שמסתמכות על query strings לדפי מוצר הוא חוסם גם כתובות קריטיות. הפתרון הוא חסימה ממוקדת כמו /*?sort= או /*?color= במקום גישה גורפת. גוגל תומך בתווים מיוחדים כמו * ו-$ בתוך כללים, אבל לא כל מנוע חיפוש מפרש אותם באותה צורה, אז כדאי לבדוק התנהגות בפועל. עוד נקודה שחשוב לזכור: קובץ רובוטס הוא ציבורי לחלוטין, כל אחד יכול לפתוח את הכתובת ולראות בדיוק אילו תיקיות ניסיתם להגביל את הגישה אליהן, כמו שלט "לא להיכנס" על דלת פתוחה.
בנוגע לחסימת בוטים של בינה מלאכותית כמו GPTBot, לרוב העסקים בישראל ההשפעה על דירוגים זניחה. הדירוגים תלויים הרבה יותר בסריקה יעילה ובתוכן חזק, אז עדיף להתמקד בזה קודם.
טבלת השוואה - שגוי מול נכון
| ❌ שגוי והסיכון | ✅ נכון והתוצאה |
|---|---|
| User-agent: * Disallow: / עוצר סריקה של כל האתר לחלוטין. |
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php חוסם רק את לוח הניהול, התוכן הציבורי נגיש. |
| Disallow: /assets/ גוגל לא מצליח לרנדר את העמוד ועלול לפרש אותו כשבור. |
Disallow: /cart/ Disallow: /checkout/ חוסך תקציב סריקה על שלבי רכישה חסרי ערך אורגני. |
| Disallow: /*? שובר דפי מוצר בפלטפורמות שמסתמכות על פרמטרים. |
Disallow: /*?sort= Disallow: /*?color= חוסם פילטרים רועשים בלי לפגוע בכתובות ליבה. |
| אין הגבלת גישה לחיפוש פנימי אלפי כתובות כמו /?s= נוצרות ומרוקנות את תקציב הסריקה. |
Disallow: /?s= Disallow: /search/ מונע יצירת דפים חסרי ערך שפוגעים בגילוי תוכן חשוב. |

איך כותבים קובץ robots.txt ובודקים אותו ב-Google Search Console
שלושה צעדים מעשיים ליצירת הקובץ
פתחו עורך טקסט בסיסי, שמרו את הקובץ בפורמט UTF-8 בלי עיצוב מיוחד, והעלו אותו ישירות לתיקיית השורש של האתר. גם באתרים עם 10,000 דפים, הקובץ בדרך כלל לא עובר 50 שורות אם עובדים עם דפוסים במקום רשימות כתובות. בוורדפרס אפשר לערוך דרך תוספי SEO או להניח קובץ פיזי בתיקייה הראשית. לעולם אל תתייחסו למסמך הזה ככלי פרטיות, גם לא לגיבויים או חשבוניות, כי הגנה באמצעות סיסמה היא השכבה הראשונה החובה.
הנה קובץ בסיסי שמתאים לרוב אתרי העסקים בישראל, החליפו את כתובת מפת האתר בכתובת האמיתית שלכם:
# חסימת אזור ניהול
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
# חסימת דפי רכישה וחיפוש פנימי
Disallow: /cart/
Disallow: /checkout/
Disallow: /?s=
# הוספת מפת אתר לגילוי מהיר
Sitemap: https://www.domain.co.il/sitemap.xmlשימו לב להערות עם סימן # בתוך הקובץ. הן לא משפיעות על ההתנהגות אבל מצילות חיים אחרי חצי שנה כשאף אחד לא זוכר למה נחסם נתיב מסוים. רשמו תאריך עדכון וסיבה לכל שינוי, למשל "# חסימה זמנית לקמפיין" או "# עודכן מרץ 2026". לפני שחוסמים /cart/ או /checkout/, כדאי לבדוק מה באמת יושב בכתובות האלו, כי לפעמים עמוד "תנאי רכישה" שמקודם אורגנית מוטמע שם בטעות והחסימה תפגע בנראות שלו.
בדיקה ב-Google Search Console בלי הפתעות
הבדיקה ב-Google Search Console לוקחת פחות מ-5 דקות וכל בעל אתר יכול לבצע אותה לבד, גם בלי רקע טכני. הצעד הראשון הוא הכי פשוט: פתחו בדפדפן את הכתובת domain.co.il/robots.txt וודאו שהקובץ נטען עם קוד תגובה 200. אם מופיע 404, גוגל מתנהג כאילו אין הנחיות בכלל ופשוט סורק הכל. אחרי שמאשרים שהקובץ במקום, השתמשו בכלי URL Inspection כדי לבדוק לפחות 5 כתובות: 2 שחייבות להיסרק בהצלחה ו-3 שצריכות להישאר חסומות.
אם רואים הודעת "Blocked by robots.txt" על דף שאמור להיות נגיש, תקנו את הכלל ובקשו אינדוקס מחדש. חשוב לדעת שאחרי שינוי בקובץ, לפעמים לוקח כמה ימים עד שגוגל מבקר שוב וקורא את הגרסה המעודכנת, אז אין סיבה להיבהל אם התוצאה לא מתעדכנת מיידית. עקבו אחרי דוח הדפים וחפשו קפיצות פתאומיות ב-Blocked by robots.txt, כי אחרי כל העלאה לאוויר זהו איתות האזהרה המהיר ביותר שמשהו השתבש.
תחזוקה שוטפת - כי קובץ שנשכח הוא קובץ מסוכן
בדיקה רבעונית של 5 דקות יכולה לחסוך שבוע שלם של "למה ירדה לי התנועה". מצאנו שכ-1 מתוך 10 מעברי אתר חפוזים מאבדים את קובץ ה-robots.txt בדרך, אז זו בדיקה קריטית אחרי כל שינוי אחסון או CDN. תיישרו את הכללים עם מפת האתר והקישורים הפנימיים כל 90 יום, כדי שהדפים הרווחיים ביותר תמיד יהיו קלים לגילוי ככל שהאתר גדל. בלקסה אנחנו ממליצים לשלב תחזוקת קובץ רובוטס כחלק מתהליך העבודה הרגיל, בדיוק כמו בדיקת מיקומים וניתוח מגמות.
קובץ robots.txt אולי נראה כמו פרט טכני קטן, אבל הגדרה שגויה שלו עלולה לגרום לגוגל להתעלם מהאתר שלכם לגמרי ולאבד לקוחות שמחפשים בדיוק את מה שאתם מציעים. הידע שצברתם כאן מספיק כדי לטפל בקובץ הזה בצורה נכונה, באופן עצמאי, עוד היום.